








A practical Python tutorial on Random Forest
Before starting: Decision Trees
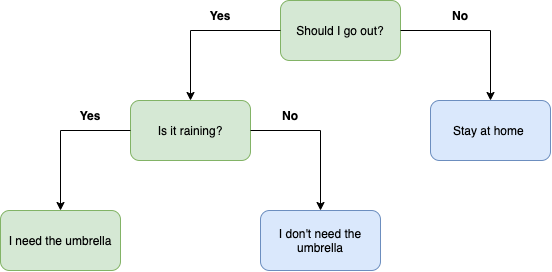
Since the random forest model is made up of multiple decision trees, before starting with random forests, it would be wise to start by defining what is a decision tree and how it works briefly. A Decision tree starts with a basic question, such as, Should I go out? After that, you can ask a series of if/else questions to reach the final answer. For example, looking at the below figure, you can see that if the answer is yes, you can continue asking yourself Is it raining? If yes I can conclude that I’ll need an umbrella. These questions make up the decision nodes in the tree, acting as a means to split the data. Each question helps an individual to arrive at a final decision, which would be denoted by the leaf node. In other words, learning a decision tree means learning a sequence of if/else questions that gets us to the true answer most quickly.
Random Forest and Ensemble Learning
Ensemble learning is a methodology that combines multiple machine learning models to create a more powerful one, aggregating their predictions to identify the most popular result.
Random Forest, as its name suggests, is essentially a collection of individual decision trees that operate as an ensemble. This is useful to resolve the main drawback of decision trees, which is the tendency to overfit the training data. Therefore, the idea of Random Forest is to build many trees, slightly different and independent from each other, where all of which work well and overfit in different ways, but by averaging their results it is possible to reduce the amount of overfitting.
Moreover, the random forest algorithm utilizes both bagging and feature randomness to create an uncorrelated forest of decision trees. Feature randomness generates a random subset of features, which ensures low correlation among decision trees. This is a key difference between decision trees and random forests. While decision trees consider all the possible feature splits, random forests only select a subset of those features. Consequently, each tree will learn how to get the target label with a subset of features.
Let’s practice
It’s time to put our hands on the keyboard and write code. First of all, you should know that scikit-learn implements two types of random forest: Random Forest Regressor and Random Forest Classifier. Let’s see both in a few steps.
Random Forest Classifier
To build a random forest classifier, one of the main hyperparameters to set is the number of trees in our forest, called estimators. Let’s say we want to build a forest of 100 trees. Remember, as above mentioned, these trees will be built completely independent from each other, and make random choices to make sure they are distinct. Moreover, the algorithm randomly selects a subset of the features and looks for the best possible test set involving one of these features. The amount of features that are selected is controlled by the max_features parameter. Ok! Let’s code.
import sklearn.datasets as datasets import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split # loading the breast cancer dataset cancer = datasets.load_breast_cancer() df = pd.DataFrame(cancer.data, columns=cancer.feature_names) # Do some pre-processing if necessary # Implementing the model X = df # data without target class y = cancer.target # target class X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42) model = RandomForestClassifier(n_estimators=100, random_state=42) model = model.fit(X_train, y_train)
In general, the first rows of code are the traditional operations that are used to do before feeding a model with prepared data. Therefore, I’m not going to deepen the meaning of those rows. But in brief:
- I’ve loaded a toy dataset from scikit-learn repository about breast cancer.
- I’ve created a dataframe and split into two subsets: X containing the overall data, and y containing only the class label (what we want to predict)
- Data has been split into training and test sets.
The RandomForestClassifier class has different hyperparameters (I’m going to cover soon the most important ones), but the most basic one is the number of estimators n_estimators. Once the model has been trained (model.fit(X_train, y_train)) it is possible to make predictions.
y_preds = model.predict(X_test)
As a result, the method predict returns an array with the predicted class labels. Each index of this array coincides with the dataset indexes. In other words, this means that the index 0 of the y_preds array contains the predicted label for the row with index 0 in the dataset and so on.
Let’s see how to print your Random Forest
Random Forest Classifier: Evaluating the model
Equally important to model building is to check if our powerful and majestic creature is working well. This step is fundamental because helps us to understand how our model is behaving on the dataset and if it is necessary to go back to preprocessing phase. In scikit-learn, there are different methods to check the model’s performance. The most common are: Accuracy, Precision, Recall, F1 Score.
y_preds = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_preds)}")
print(f"Precision: {precision_score(y_test, y_preds)}")
print(f"Recall: {recall_score(y_test, y_preds)}")
print(f"F1 Score: {f1_score(y_test, y_preds)}")Random Forest Regressor
In brief, when the problem is to predict a number we should consider the idea to use a regressor model. Notably, Random Forests can be employed also for regression, in fact, scikit-learn provides the class RandomForestRegressor. The concept is the same explained in the previous paragraphs, the difference is that the classification version of random forest predicts a label (the target class), instead, the regression version predicts a number.
Prepare the data
First, let’s load the Boston dataset through scikit-learn (load_boston()). This dataset is about real estate in Boston, where the target is the home price given its characteristics.
# Let's do the same but for regression from sklearn.ensemble import RandomForestRegressor from sklearn.datasets import load_boston boston = load_boston() boston_df = pd.DataFrame(boston['data'], columns=boston['feature_names']) boston_df['target'] = pd.Series(boston['target'])
Prepare the model
Second, after the traditional data split in the train and test set, it is possible to instantiate the RandomForestRegressor model and fit it with train data.
# prepare X and y array
X = boston_df.drop('target', axis=1)
y = boston_df['target']
# Split data in train e test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Regression version of random forest
model = RandomForestRegressor(n_estimators=100)
model.fit(X_train, y_train)You can notice that this snippet of code is the same as the classification version, the difference here is the used class RandomForestRegressor.
Evaluating the regressor
There are different evaluation metrics to evaluate a regression model (regressor evaluation).
R square
Compares your model’s predictions to the mean of the targets. Values can range from negative infinity (a very poor model) to 1. For example, if all your model does is predict the mean of the targets, its R^2 value would be 0. And if your model perfectly predicts a range of numbers its R square value would be 1.
from sklearn.metrics import r2_score y_preds = model.predict(X_test) print(r2_score(y_test, y_preds))
Mean Absolute Error (MAE)
MAE is the average of the absolute differences between predictions and actual values. It gives you an idea of how wrong your model predictions are.
from sklearn.metrics import mean_absolute_error
y_preds = model.predict(X_test)
mae = mean_absolute_error(y_test, y_preds)
# How MAE is calculated
df = pd.DataFrame(data={"actual_values": y_test,
"predicted_values": y_preds})
df['differences_abs'] = abs(df['predicted_values'] - df['actual_values'])
print(df['differences_abs'].mean())Mean Squared Error (MSE)
MSE is the average of the square of differences between predictions and actual value.
from sklearn.metrics import mean_squared_error
y_preds = model.predict(X_test)
mse = mean_squared_error(y_test, y_preds)
# How MSE is calculated
df = pd.DataFrame(data={"actual_values": y_test,
"predicted_values": y_preds})
df['differences'] = df['predicted_values'] - df['actual_values']
df['sq_diff'] = np.square(df['differences'])
print(df['sq_diff'].mean())
Hyperparameters you should take into account
Now you are able to define a random forest and evaluate it, but it’s not over yet. If your model does not behave well you could consider the idea to tune its hyperparameters. In practice, a hyperparameter is a parameter of the model whose value is used to control the learning process. The most important hyperparameters to tune in the random forest are:
- n_estimators: number of trees, a high value is good, in this way the mean of results is more robust, but it could take more time to fit
- max_features: number of features for each tree. This hyperparameter determines the randomness of a tree, a little value means a low probability of overfitting.
- max_depth: the depth of the tree. This is useful to prevent overfitting
It is possible to manually tune these hyperparameters by setting different values at each iteration of your experiments, but you should know that one of the best ways to find the best values for hyperparameters is the grid search (see grid search article for more details).
Conclusion
Random Forest is one of the widely used models not only for its reliability but also for its simplicity. Indeed, a machine learning model based on the random forest is easier to explain than others to people with different backgrounds.
In conclusion, If you are new to machine learning I suggest you is to put the hands-on project, for example, you can consider the idea to do more practice on Kaggle where a lot of projects are proposed every day.






1 Comment
Good luck!